??? SSD ??? KVCache ????????????? 4 ???????????
?? GMI Cloud ? Tensormesh ??????????????????
????????
- ??? SSD ??? KVCache ????????? Token ???Time to First Token, TTFT???? 4 ??
- ???????? 3% ????? 50%?????????????????????????
- ??????????????????????????????? AI ?????????????
- ?????? KV ???????????? GPU ??????????????????????????
??????????? KV Cache ?????????? LLM ??????????????????????? AI ?????????????????????????????????????????
????????
1. ??????????????
???????????????????????????GMI ??????????????????????????????????????????????????????
???????
- ???????? AI ???????????? 1 ?? 10 ??????
- ????????????????????????????????????????????????????
- ??????????????????????????????????????
- ??????????????????????????????????????????????????????
??????? KV Cache ????????????????????????
2. ????
????????????
- ?? vLLM????? KVCache ???
- ?? LMCache ? vLLM???? Tensormesh ?????
????????????
- ???????KVCache?????????????
- ?? + ??? SSD ??????????? KV Cache ???????
???????????????????????????????
3. ????
??????? KVCache ?????
- ????? 1.4 ?? TTFT ???
- ?????????KV Cache ???????????????????????
SSD ???KVCache???
- ??? 4 ?? TTFT ???
- ??????????????????? 50%?
- ??????????????????
???????????? KV ???????????????????
????????????? SSD ??????????? KVCache ???????????????????
4. ????
? Token ???TTFT?
TTFT——????????????——?????????????? 4 ???????????????????
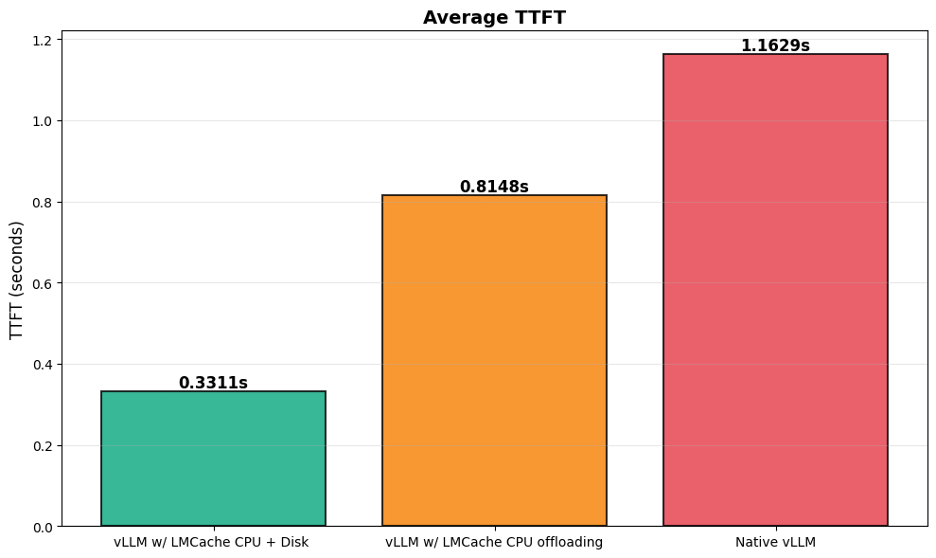
?? KV Cache ???
??????????????KV Cache ???????????????????? 50%????????????????????
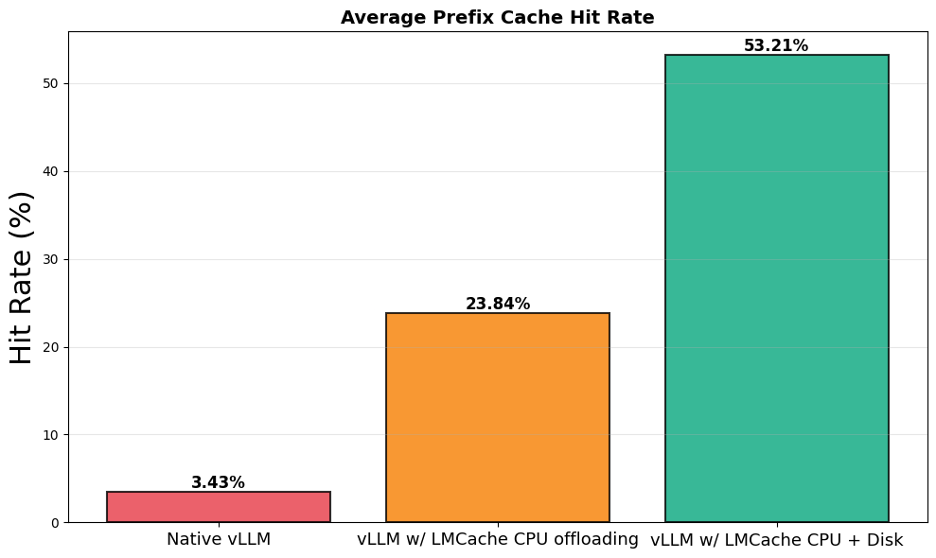
????????
?? TTFT ??????????????????????????????????????????????????????????
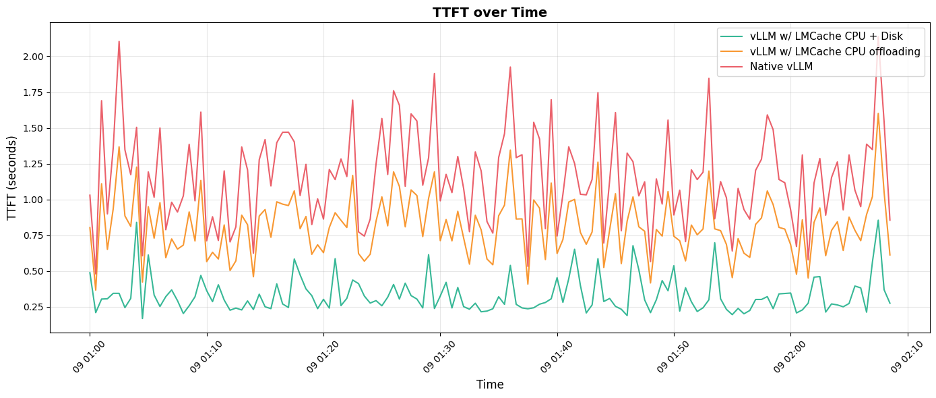
KV Cache ? LLM ???????
???????? GMI ??????????????????????????????
- ???????????? KV ??????????? GPU ????
- ???????????????AI ?????????????
- ?????????????????????? QPS?
- ?????????SSD ?????????????? RAM ???
?????GMI Cloud ??????????????????????“???????????????”??????????????????????????????????????
?????????????
- ???????????????????????????
- ??????RAM + SSD??????????????
- LMCache ???????????????? vLLM ??????
- ?????????????AI ??????? LLM ?????????????
Tensormesh ??
Tensormesh ??? AI ???????????????????????????? AI????????????????????????? GPU ??????? 10 ??????????????????????????Tensormesh ?????????????????? Laude Ventures ??? 450 ?????????
GMI Cloud ??
GMI Cloud ?????? GPU ??????????????? AI ???????????????? NVIDIA ??????GMI ????? GPU ????? NVIDIA Blackwell ?? H100 ? H200 GPU ??????GMI ???????????????????????? AI ????????????????
