???Yihua Cheng ?Yuhan Liu ? Jiayi Yao * ?Yuwei An?Xiaokun Chen?Shaoting Feng ? Yuyang Huang?Samuel Shen?Kuntai Du?Junchen Jiang
???TensorMesh&?????
??
?????????LLM???????????????????????????????????????????????????????????KV Cache???????????????????????????? GPU ??????????????? ?????????????KV Cache?????????? LMCACHE???????????? KV Cache????????????????? LLM ?????vLLM ? SGLang???? KV Cache??????????????LMCACHE ? LLM ??????? KV Cache???????? LLM ??????token??????? KV Cache?????????????????????????????????????????????PD??????????????LMCACHE ???????????????????1?????? KV Cache????????????????????? I/O ??????????2????? KV Cache??????? LMCACHE ??????????????3?????? API??????????????????????? GPU?CPU?????????????????????????LMCACHE ? vLLM ?????????????????????????????? 15 ???????????LMCACHE ???????????????? KV Cache??????????????????????https://github.com/LMCache/LMCache?
1. ??
?????????????????????LLM ???????????????????????????????????????????????LLM ????????????——?????????????????????????????
?? LLM ???????????????????????????????????????????????????????? LLM ????????????? I/O ?????????????? GPU ? GPU ????????????token????????????token??????????????????????????????????
????????????????????????????????????????????????????

??????????????????????????????????????????LLM ???????Prefill??????Prefill?????????????? —— ????????????????????token???????Prefill? LLM ??????? KV Cache?????????????????????????????????????????????????????????? KV Cache??????????????????????????????????Prefill????token?????TTFT???? GPU ?????
PD????????????Prefill????????????????decode????????????????????????????????????????decode???????prefill?????GPU ?????????????????????prefill????????decode??????????PD??????????prefill???????????????????? KV Cache??????????decode???????????????????decode?????
?????????LLM ?????????? KV Cache?????????????????????????????? KV Cache????? KV Cache???????????????????? KV Cache??????????????????????????KV ?????????????????????????????????????? vLLM ? SGLang??????
???? LMCACHE—— ???????????? KV Cache????????????? LMCACHE?KV Cache???????????????????????????????????CPU ????????????? Redis???????????????RDMA?NVLink????
LMCACHE ??????????
- ????????????????????? KV Cache????????????????????????????? KV Cache????????????? GPU ??????? / ???????????????????????? KV Cache??????????????????????????? / ?? KV ???????????? GPU ?????????????????????? KV Cache?????????????????
- ???????????????????????????????????????2025 ?????? 15-20 ???????????????????????????? LLM ????????????????? GPU ???? KV ????????? LMCACHE ??????LMCACHE ????????? KV ????????? LMCACHE ????????????????????????? API?
- ??? KV Cache?????LMCACHE ???????? KV Cache?LLM ????????????????????????????????????????? KV Cache? API????? API ??????????????????????????? KV Cache???????
???????LMCACHE ??????????????????????? PD ???????????????????? KV Cache????????? API????????15 ???????? 2 ???????????LMCACHE ?????????????????? KV ???????????????
????????????????? 2 ???LMCACHE ??????????? 3-6 ????????? 8 ????????? 9 ???
2. ??
2.1 ???????????
?????LLM ?????????????????????? LLM ??????????????????????????????????????? LLM ?????????????
????????????????????????????????????? —— ????token???token?????????????????????????????
- ??? LLM ??????????????????????????????? LLM ????
- LLM ????????????????????????????????token?????? LLM?
- ??? LLM ??????????????? / ???????????????token?
- ????????????????????????????????????????
??????????????????? 95 ?? / 99 ?????????????????????????????????????????????????????????????????????????????????
?????????????????
- ??????????????????? 8-16K token????token?????TTFT????prefill?????
- ??????token????ITL?????????????? GPU ??????token?????????
- ??????????????????????????????????????
2.2 KV Cache??????????
KV Cache?????????????????? —— ???token????token??????? K ? V ?????????? GPU ????KV Cache????????????token?????????????? LLM ??????????
????? Transformer ????????????????????????????????????KV Cache?????????????????????
- ????????? KV Cache???????????????? KV ???????????????????????????????????????????????????????????????????????prefill????????????? TTFT ?????? GPU ?????
- PD???????? KV Cache????????????prefill?????????????decode??????token????????? GPU ??????????????????????????prefill??????????????
KV Cache?????
?????????? KV Cache??? GPU ???CPU ???DRAM?NVMe ???????????????????
- ??????????? KV Cache???????????????? KV Cache???????????????????????
- PD ???? GPU ?????? KV CaCHE????? PCIe?NVLink ? RDMA???????prefill???decode???????????
2.3 ?? KV ?????
????????????? PD ???????????????????????
?? 1??????? I/O ??
?? KV Cache???????? PyTorch ????torch.save/torch.load????????????????????? 1GB????????????????????? KV ??????????????????????????????????????????? CPU-GPU ?????
????????????? vLLM ? SGLang??????????????????????????????????? 16-64KB???????? KV Cache????????????vLLM ? Llama3.1-8B-Instruct ????? 62.5KB ????????????????????????????? KV Cache??????????????????? KV Cache?????????? I/O ???????????????????????????????????????? 8 ??? Thor-2 400Gbps ??????? AMD GPU ???????????????? 16MB ????????????????????????????? 1-2MB??????? PCIe 5.0 ????? 75-80%?
| ???? | ????? |
|---|---|
| 64KB | 4GBps |
| 256KB | 13GBps |
| 1MB | 30GBps |
| 10MB | 46GBps |
| 16MB | 49GBps |
| 100MB | 49GBps |
? 1??? RCCL ????????????????
?? 2????????????
?? AI ???????? LLM ???????????2025 ????? 4 ??????? LLM ???????????????????????????????????? GPU ??????????? KV Cache?????????? vLLM ??????????? KV Cache????????KV Cache?????????????????? KV Cache????????????????????????????????????????????
?? 3???????? API
?? KV ???? LLM ??????????? LLM ???????????????????????? KV Cache??????????????????????????????????????????????????????????????????????????????????????????????? KV Cache?????????????????? CPU ?????????token KV Cache????
????????? KV ???????????????2025 ?????? LMCACHE ??????????????????????????????????????? KV Cache???????????????????????????????? API?????????? KV Cache??? KV Cache?????????? KV Cache?
2.4 ???????????
?????? KV ????????????????????
????
? 2025 ? 1 ? vLLM ???????????????????????? NVIDIA ? Dynamo?AIBrix?llm-d?SGLang OME ? KServe??????????????? Kubernetes ??????????????????????????????? KV ?????vLLM ????Dynamo?llm-d ? KServe ??? LMCACHE??
?????? KV ??
vLLM ? SGLang ???????????? GPU-to-CPU KV ??????????????????????????????? KV Cache????????????? 7 ???????? LMCACHE ???
KV Cache???
Mooncake?Redis?InfiniStore ? 3FS ?????????????????????????????????????? “???”?????????????
????
Fireworks AI?Together AI ????? API ????????????????????????????????????????????
??????
????????? KV Cache????????????PD ??? KV ?????????????????? HuggingFace Transformers ??????????????????????????????? SGLang ? vLLM ?????????????
3. LMCACHE ??
LMCACHE ???????? KV Cache????????????????????????? KV Cache?????????????????????? PD ??????????????
?? KV Cache????LMCACHE ??? LLM ????????? / ???????? 2???????????????? KV ??????????????? vLLM ? SGLang ???????????????
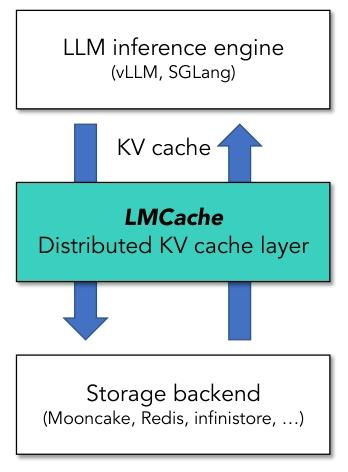
?2 ???? LMCACHE ??????????????????
3.1 ??
????????LMCACHE ????????? KV ??? GPU ?????????????? 3 ??????????????? KV ????????????????????
????
???????????? KV ??????token??????????? GPU ?????????????????token????????????????????token???????????????????????????????token? KV Cache??????
????
?????????? KV Cache??????? KV ?????????token????????????????token????????????? ID ??????? —— ??????????????????? GPU ????? GPU ???? KV Cache????? GPU ????????????? 4.2 ?????????????????? ID??????????????? KV Cache? CPU ?????
????
?????????token? KV Cache???????????????????????????????????token????????? KV Cache?????token??? LMCACHE ??????? KV ???????? LMCACHE ???????token??????token??????????token?????
3.2 ????
LMCACHE ???????????????????
LMCACHE ?????????
??????????? LMCACHE ?????? KV Cache? GPU ???????????????????????? KV ???? CPU ????? PD ???GPU-GPU ?????????????????????? GPU ???????? I/O ?????????????? vLLM ? SGLang ????????????16-64KB???????? GPU ????????
LMCACHE ?????????
????????????????????? API????????????????? KV ????????????????????????????????????????????????????????????????
LMCACHE ????????????????????????????????? —— ???????????????????????????????????

????? LMCACHE ????????????
4. ????
LMCACHE ?????????? KV ???????????????? LLM ??????LMCACHE ???????????
?? LLM ???????????? KV ????????? Llama?Qwen?GPT-OSS ?????????? 20KB-63KB????????????????????????
KV ???????? LLM ???????????????????????????? CUDA ??????????????????????? CUDA ????? CPU ????????????????????????
LLM ??????????????? KV ????????????????????????????????????
???????????????????????????????????? LMCACHE ??????
4.1 ????
?????? KV ??????? I/O ?????LMCACHE ???????????
??????
LMCACHE ???????? KV ?????????????????????????? 256 ?token?????????? GPU ???????????????????? 16 ??? GPU ?????????????????????????? CPU ?????????????????? GPU ???????????????????? GPU ???LMCACHE ???? CUDA ???????????
???? / ????
LMCACHE ?????????????? CPU ?????????????????? KV Cache???????KV Cache?????????????????????? KV ????? CPU ?????????????????????????????? KV Cache????????????????????? CPU ??????????????????LMCACHE ????????????????????????????? GPU ?????????????
???? KV ????
LMCACHE ???decode????????? KV cache?????????????????????????????????????? LMCACHE ???????????????????? I/O ???
4.2 ???I/O ??
LMCACHE ???????? LLM ????????????decode????KV Cache????????????????????????????? LLM ??????????LMCACHE ???????? LLM ????? I/O ??????
?????
LMCACHE ????????? KV ????????????????????????????????????? CUDA ?????????????????? KV ????? GPU ???????????????????????????? KV ??????????????? KV ????????? KV ????????????????????????? KV ??????? GPU ???????????????????
???????
??????????????????? KV Cache??????????????????100 ??????????????????? 50 ???? 50 ?????????LMCACHE ??????????????? KV ???????????????????????????? CPU ???????????????????? KV ????????????????????????????????????????SLO???????????????????
????
?? LMCACHE ????????????????????? CPU ?????? 5%-10% ??????????????LMCACHE ????????????????????????????????????????????????????????????????????????? CPU ?????????????????????? KV ?????????????????? CPU ?????????????????????? KV ?????????????
4.3??????
??? KV Cache?????????????????????????????????????????????????????LMCACHE ??????????????????
?????
?? KV ???????????? GPU ???????????????LMCACHE ???????????????????????? KV ?????????????? CPU ???????????????LMCACHE ??????????????????????????????????????????????????????????????????????????????????????????? PCB ???????
????
vLLM ???????? GPU ???????????????????????????LMCACHE ???????????? CPU ?????????????????????????
?????Start pointer??GPU ???????????????
?????Current pointer?????? CPU ??????????
?????End pointer???????????????????
?? 4 ??????????????
- ??????State #1???????????????? / ?????????????????????
- ??????State #2???????????????????????????????? CPU ???
- ???????State #3???????????????????????????????????????????? GPU ???
- ?????State #4????????????????????????????
?????????????????????????????????????????????????????????????? GPU ? CPU ????????????????????????????????????????????????????????????? 1 ?????????? 3 ??????????????????????? 2 ??????????????????????????????
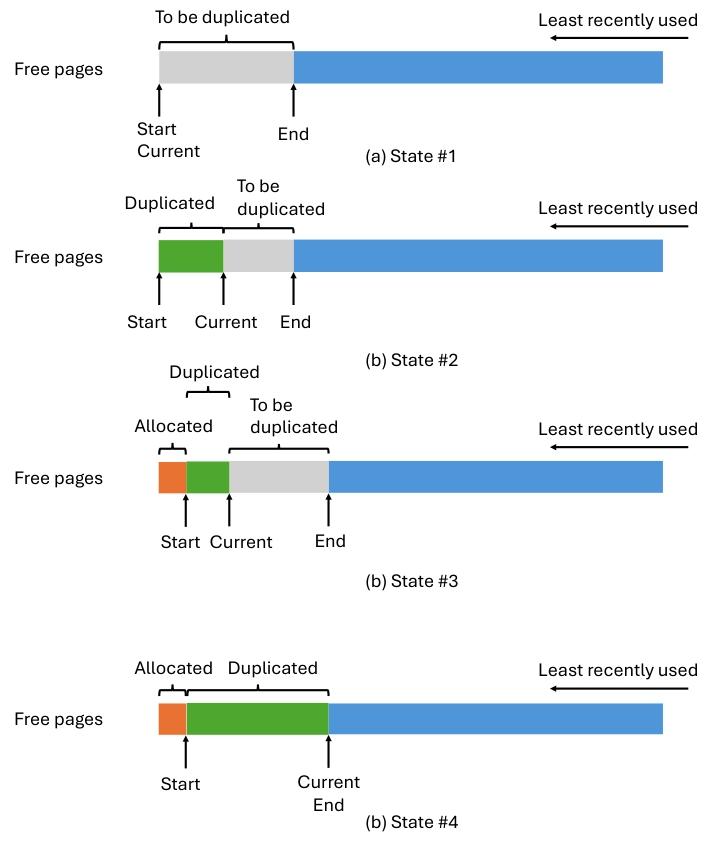
???????????????????????
5. ?? KV Cache??????????????
vLLM ? SGLang ??? LLM ???????????????????????????2025 ?????? 15-20 ?????????????????????????????????????????????????????????????? KV ???????????? LMCACHE ?????????????
????????LMCACHE ????? KV ????????? KV ?????????????????????????????LMCACHE ???????
?????? vLLM ??LMCACHE ???????????
???????token?????????????? LMCACHE ??????? LMCACHE ???????????token???????
???????????????KV ??????????????????
? 2 ??????????????? API ???????????????????????
| ???? | ?? |
|---|---|
| get_num_new_matched_tokens(query) ? matched_tokens | ?? LMCACHE ????????token?? |
| update_state_after_alloc(query, blocks, num_external_blocks) | ????????? LMCACHE ???? KV ?? |
| build_connector_meta(scheduler_output) ? kv_connector_metadata | ?? KV ??? LMCACHE ??? GPU ????????????? KV ????? GPU ????? |
| start_load_kv(kv_pointers) | LLM ?????????????? GPU ???? KV ?? |
| wait_load_kv(kv_pointers, layer_id) | ?? KV ????????????????? |
| start_store_kv(kv_pointer) | ???????? KV ?????????? |
| wait_store_kv(kv_pointer, layer_id) | ?? KV ????????????? KV ??????? |
? 2 ??????? LMCACHE ??????????? KV ??????????????? vLLM ????????? LMCACHE KV ???????token??????????????????????????????????? LMCACHE KV ????????? KV ?????
????????????
?????????????
get_num_new_matched_tokens??? LMCACHE ???????token???update_state_after_alloc???? LMCACHE ?????token????? vLLM ?????????????????????????token??? 0???
build_connector_meta?????????????? KV ??????????????????????????????
??
start_load_kv????? KV ??? GPU ???????? LLM ??????????
wait_load_kv????? KV ???????????? KV ????????????????
wait_store_kv????? KV ??????????start_store_kv???????? KV ??????
???????????
??? LLM ????????
start_load_kv???????? KV ????? GPU ???????? KV ??????? GPU ??????????????? LLM ????????
start_store_kv???? KV ????????????
6. ?????
?????????????? KV ?????????????????????????????token?????????????????????LMCACHE ???????? KV ??? API?? 3??????????????????
LMCACHE ? KV ?????????????????????????????????????????????????????? LMCACHE ????????????????????????????????
?? KV Cache?????
??????????????????????????
?????
lookup(tokens)????????????????? LMCACHE ???????????token??????
query_ip(instance_ids)??? ID ??? IP ???????????token????? IP ???
KV ????
??? KV ?????????????????????? KV ?????move(source, destination, tokens)?????token??? KV ??????????????
KV ????
????????????????????????clear(tokens, instance, location)????????????????? GPU ???CPU ??????token KV ???
GPU ????? KV ??
???????????????????????? GPU ????????????pin(instance, location, tokens)??????????token? KV ?????????????GPU ????
????????????????? KV ?????compress(tokens, instance, location, compression_method)????????????????????????? KV ??????????????????????????????????? KV ???
| ?? | ?? |
|---|---|
| lookup(tokens) ? {instance_id: hit_tokens} | ???????token??????? KV ??????????token? |
| query_ip(instance_ids) ? IP | ?????? ID ? IP ?? |
| move(source, destination, tokens) | ???token? KV ????????????? |
| clear(tokens, instance_id, storage_device) | ?????????????????token? KV ?? |
| pin(tokens, instance, storage_device) | ???token? KV ????????????????? |
| compress(tokens, instance, storage_device, compression_method) | ????????????????????????token KV ??????????? |
? 3?LMCACHE ?????????
7 ??
7.1 ????
???????????? LMCACHE?? 4???????? LMCACHE ??????????
??
?? LMCACHE ??????????????????????meta-llama/Llama-3.1-8B-Instruct?meta-llama/Llama-3.1-70B-Instruct?Qwen/Qwen2.5-Coder-32B-Instruct?Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8?Qwen/Qwen2.5-72B-Instruct?
???
??????????????????LongBench ?????????????? vLLM ????????????????
??
???????? GMI Cloud ??? 8×H100 ?????????????????????? H100 GPU?
??????????????? GPU ??????? CPU ???? KV ??????????
PD ????????????????????????? GPU ????? NVLink ???
????
?token?????TTFT????????
token????ITL????????token????????
?????????? CPU ??? PD ?????????
????
vLLM?????????? GPU ??????? KV ???
???? 1?2?3??????????????? GPU ????????
| ?? | ??? / ??? | ???? | ?????? |
|---|---|---|---|
| CPU ?? | ??? | – | ??? CPU ???? |
| ????? | ??? | ??? | ?????????? |
| PD ?? | ??? | NVLink | PD???? |
? 4???????
7.2 ??? CPU ??
? CPU ??????? 4??????????????????????????????????? LLM ???? 10K token?? 12 ? PDF ????????????????????Llama-3.1-8B-Instruct ???? 20K token?????????????????????LLM ???? 100 ?token???????????? 40 ???????????????QPS?????? LMCACHE ??? KV ????? CPU ??? 500GB?
?? 5 ???LMCACHE ? TTFT ? ITL ???????????????????? QPS?? QPS=1???LMCACHE ??????????????????????????????? 2.3-14 ??????? TTFT?? ITL ???LMCACHE ???????? —— ????????token???????token????????????????? 1 ? 2 ????? Qwen3-Coder-480B ???

?5???? LMCACHE ???????????? TTFT?ITL ? QPS ??
LMCACHE ??????
??? GPU ??????? KV ??? vLLM ?????????LMCACHE ?? CPU ????? KV ???????????????????????? CPU-GPU ??????????????????
???? 1 ???? KV ?????????????????? 2 ????????????? LMCACHE????????????????????????
7.3 ????????
??????????? 4???? LMCACHE ?? 15Gbps ???? GPU ????????????????? LongBench ?? TriviaQA ??????????????????? vLLM ?????????????????? QPS ??????
?? 7 ???LMCACHE ??? QPS ?????????????????????? 1.3-3 ???????????????????? CPU ????? KV ??????????????
????????????? KV ???????? CPU ?????????????????????????????????????????????????????????? 7.7 ????????

?7???? LMCACHE ?????????????? TTFT?ITL ? QPS ??
7.4 PD ??
? PD ?????????????????????????????? LMCACHE ? vLLM ?? PD ???????? 8K token??? 200 token???? 8 ???LMCACHE ? 95 ?? TTFT ???? vLLM ?? PD ?????? TTFT ???LMCACHE ?????? —— ???????? TTFT ?? 1.53-1.84 ???? ITL ?? 1.12-1.66 ??

?8????????? LMCACHE ? vLLM ?? PD ??????????
LMCACHE ??????
LMCACHE ?? PD ?????????????????????????????? KV ?????? GPU ??????????????????????? KV ????????????????
?????vLLM ?? PD ?????? NIXL ?????????????????? KV ??????????????????? KV ?????????????????????????? KV ??????????????? GPU ??????????????????????????? 4 ??????
? 11 ??? LLM ???????????????????????????????? KV ??????LMCACHE ? vLLM ?? PD ????????????????? LMCACHE ?????? KV ?????????????????? PD ????????????
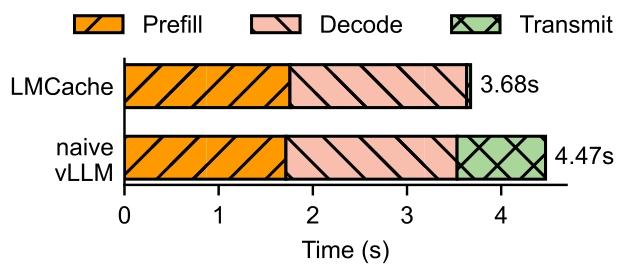
?11???? LMCACHE ? vLLM ?? PD ?????????????????
7.5 ????????
???????????????? LMCACHE?????????????????????????????????????????????????????????????????? 4K token?
????????????????? Sao10K/L3-8B-Lunaris-v1 ??????????????????????????????????????? 1 ??????
?? 6 ?????? QPS ??LMCACHE ?????????????? vLLM????? TTFT ? ITL???????????????????QPS ? 2-5 ??LMCACHE ????? vLLM ?? 25%?QPS ? 6 ??????? 49%?
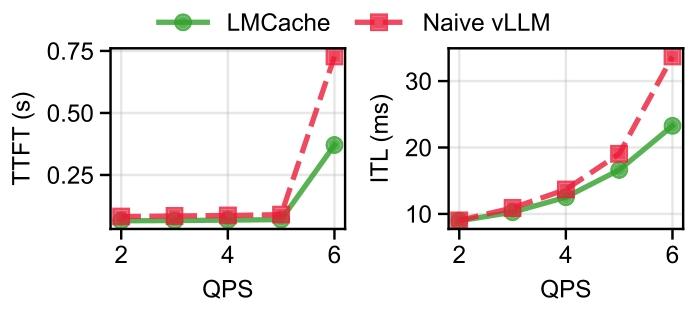
?6???? LMCACHE ??? vLLM ??????? TTFT?ITL ? QPS ??
7.6 ?????
?????? LMCACHE ?????????????????????????
CPU ??
? 5 ??? LMCACHE ? vLLM ?? CPU ??? CPU ?? KV ????????LMCACHE ????????? vLLM ?????????????????vLLM ?? CPU ????????????? LMCACHE ??????????????? CUDA ???????????????????????????????????????????LMCACHE ?????????????????????????????????
| ?? | ???? |
|---|---|
| LMCACHE | 400 Gbps |
| vLLM ?? CPU ?? | 88 Gbps |
? 5?LMCACHE ? vLLM ?? CPU ?????????
????
? 10 ??? LMCACHE ?????????????????????????????????????????????? / ????????????????????????? / ?????? KV ???????????????? 1.46 ??
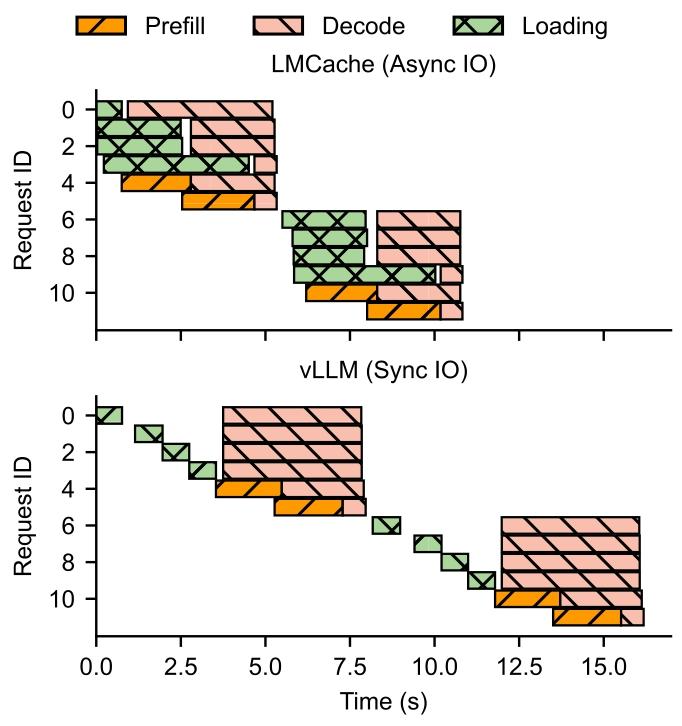
?10???? LMCACHE ?? I/O ???? KV ?????????
7.7 ?????
????????????????????????? LMCACHE ??????
????????
? 12 ??? B200 ?????????????????????????????????32 Gbps?????????????? 256K token?LMCACHE ? KV ???????????????????64 ? 128 Gbps???LMCACHE ??????????????????????????????LMCACHE ? KV ???????????????????????????????????????????????
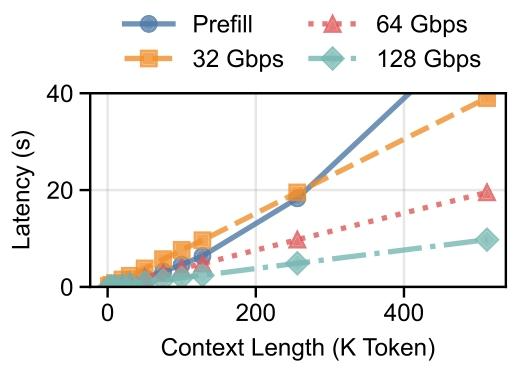
?12????????????????????? / ???????
7.8 SGLang ????
???????? vLLM?????? LMCACHE ? SGLang ??????? 9 ?????? H100 GPU ??? Qwen3-32B ???TP=2???? LMCACHE CPU ?????????? CPU ??? SGLang ???LMCACHE ??????????????? TTFT ???????? SGLang ?? CPU ?????LMCACHE ???????????? LMCACHE ???????????????????SGLang ?? CPU ???????? LMCACHE ???????????????????????? CPU / ????????????????????
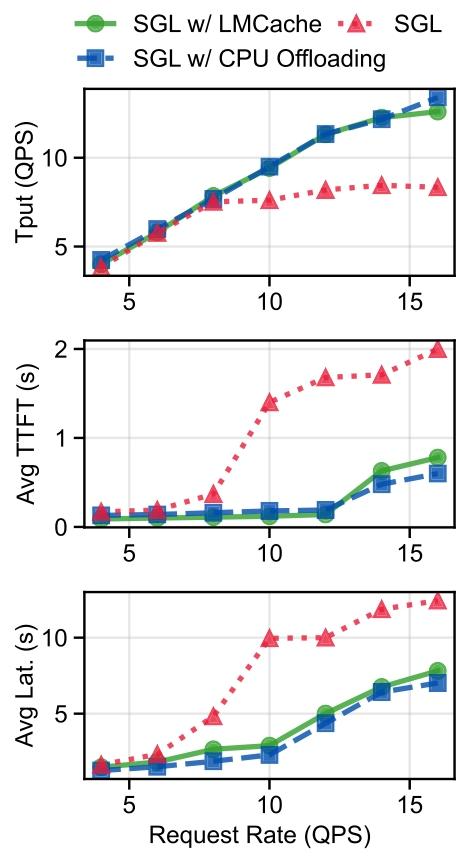
?9???????????LMCACHE ? SGLang ??????????? TTFT ?????
8. ?????????
8.1 KV ???????????
LMCACHE ????????????????????? KV ??????????? GPU ??????????????? KV ????? GPU ?????????????????????? GPU ??????????????? KV ????? CPU ???CPU ???????????????????????????????? —— ???????????????????????????????? TTFT?
??????????????????????????????????????????? GPU ????????????????????? LMCACHE ? KV ???????? 4 ???????????? KV ?????????? GPU ?????????????????????? KV ???????????????????????token????????????????????????????????????????????? KV ?????????
??????????????? CPU ??? PD ???????????????? KV ??????????????????????? CPU ???????? CPU ??? PD ????????
8.2 ???????????
???????? KV ??????????????????????????????????????????? LLM ????????? KV ??????????????????LLM ????????????????token???????????????????????????????????? KV ??????????????????? LMCACHE ????????
??????????? KV ????????????????????????????????????????????? GPU ???????token???????????????????????????????????????????????????????????????????????????? KV ??????????????????????????????????????????????????????? GPU ?????????????????????????????????
????????????????????????? KV ??????????????????????????????????? “??” ???????? KV ?????? KV ????????????????????????? I/O ??????????????????????????????? KV ???????????????
8.3 ???????
???? LLM ??????????????????????? LMCACHE ???????????
???????
??????????????????????? Docker ??????????????????? LMCACHE ?????
???????
??????????????????????????????????????????????????????????????????????LMCACHE ????? KV ??????????????????LMCACHE ???????? KV ?????????????? KV ???????????????????????
??????????????
??????????????????????????????????? KV ????????????????????????????????????? LMCACHE ?????????????????????LLM ?????????? KV ???????????
???????????
LMCACHE ????????????????LMCACHE ???? vLLM ??????? SGLang ???????????????????????????????????LMCACHE ?????????????????????????
8.4 ??????????????
LMCACHE ????? 2024 ??????????? KV ????????????????????? 2025 ????????????? ——KV ?????????? LLM ??????????2025 ???LMCACHE ?????????????????????????
??????? LMCACHE ?????????????????????????????????????????????????????????? KV ????token????????????? LMCACHE ???token?????? ——LMCACHE ????????token????????????????????? LMCACHE ???????????????????????????? LMCACHE ???
?????????????????? LLM ????????????????????? KV ???????? Rust ? C++ ?????????????? Python ?? LMCACHE??????????????Python ????????????????????????????????????????????LMCACHE ???????????????? CUDA ???
9. ?????
???? LMCACHE—— ?????????????? LLM ?? KV ??????? KV ???????????????????????LMCACHE ? LLM ??????token?????????????????????????????????????LMCACHE ???????????????????????? API????????LMCACHE ????????????????? CPU ???????? PD ????????token?????????????????????????????????????? KV ???????????????????????? LMCACHE ????????????
?????LMCACHE ????????????KV ??? AI ????????? LLM ???????????????????? KV ???????????????LMCACHE ?????????? —— ????????????????????????????????????????????????????????????? LLM ?????????? KV ??? AI ?????????????????????????????????
LMCACHE ??????https://github.com/LMCACHE/LMCACHE?
10. ??
?? LMCACHE ?????????????Baolong Mao and Chunxiao Zheng????????????Martin Hickey??? GitHub ??????Huaizheng Zhang?Siddhant Ray?Gu Zhuohan?Hanchen Li????????????Rui Zhang ??? LMCACHE ????Qizheng Zhang?Hussain Mohammad?????????
????
Best 44 large language models (LLMs) in 2025. https://explodingtopics.com/blog/list-of-llms, 2025.
Bai Y, Lv X, Zhang J, et al. Longbench: A bilingual, multitask benchmark for long context understanding, 2024. https://arxiv.org/abs/2308.14508.
ByteDance. InfiniStore: Kv cache store for distributed llm inference. https://github.com/bytedance/InfiniStore, 2025.
Caylent. Prompt caching: Saving time and money in llm applications. https://caylent.com/blog/prompt-caching-saving-time-and-money-in-llm-applications, 2024.
Chen S, Jiang R, Yu D, et al. Kvdirect: Distributed disaggregated llm inference, 2024. https://arxiv.org/abs/2501.14743.
Chen W, He S, Qu H, et al. IMPRESS: An Importance-Informed Multi-Tier prefix KV storage system for large language model inference. In: 23rd USENIX Conference on File and Storage Technologies (FAST 25), Santa Clara, CA, 2025: 187-201.
DeepSeek AI Contributors. deepseek-ai/3fs: A high-performance distributed file system for ai training and inference workloads. https://github.com/deepseek-ai/3FS, 2025a.
KServe Contributors. kserve/kserve: Standardized distributed generative and predictive ai inference platform for scalable, multi-framework deployment on kubernetes. https://github.com/kserve/kserve, 2025b.
Databricks Research. How long should you train your language model? https://www.databricks.com/blog/how-long-should-you-train-your-language-model, 2024.
Du D, Cao S, Cheng J, et al. Bitdecoding: Unlocking tensor cores for long-context llms with low-bit kv cache, 2025. https://arxiv.org/abs/2503.18773
Gao B, He Z, Sharma P, et al. Cost-efficient large language model serving for multi-turn conversations with cached-attention, 2024. https://arxiv.org/abs/2403.19708.
Ge S, Zhang Y, Liu L, et al. Model tells you what to discard: Adaptive kv cache compression for llms, 2024. https://arxiv.org/abs/2310.01801.
Gim I, Chen G, Lee S S, et al. Prompt cache: Modular attention reuse for low-latency inference. In: Proceedings of the Seventh Annual Conference on Machine Learning and Systems (MLSys 2024), Santa Clara, CA, 2024.
GMI Cloud. Gmi cloud: Gpu cloud solutions for scalable ai & inference. https://www.gmicloud.ai/, 2025.
Jegou S, Jeblick M, Devoto A, et al. Kvpress: Efficient kv cache compression for long-context llms, 2024. https://github.com/NVIDIA/kvpress.
Jin C, Zhang Z, Jiang X, et al. Ragcache: Efficient knowledge caching for retrieval-augmented generation, 2024. https://arxiv.org/abs/2404.12457.
Jin S, Liu X, Zhang Q, et al. Compute or load KV cache? why not both? In: Forty-second International Conference on Machine Learning, 2025a.
Jin S, Liu X, Zhang Q, et al. Compute or load KV cache? why not both? In: Forty-second International Conference on Machine Learning, 2025b.
Kwon W, et al. Demystifying nccl: An in-depth analysis of gpu-based collective communication. arXiv preprint arXiv:2507.04786, 2025.
Kwon W, Li Z, Zhuang S, et al. Efficient memory management for large language model serving with paged-attention. In: Proceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23), New York, NY, 2023a: 611-626.
Kwon W, Li Z, Zhuang S, et al. Efficient memory management for large language model serving with paged-attention, 2023b. https://arxiv.org/abs/2309.06180.
Kwon W, Li Z, Zhuang S, et al. Efficient memory management for large language model serving with paged-attention. In: Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023c.
Lee W, Lee J, Seo J, et al. InfiniGen: Efficient generative inference of large language models with dynamic KV cache management. In: 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), Santa Clara, CA, 2024: 155-172.
Li J, Zhang Y, Hassan M Y, et al. Commvq: Commutative vector quantization for kv cache compression, 2025. https://arxiv.org/abs/2506.18879.
Li Y, Huang Y, Yang B, et al. Snapkv: Llm knows what you are looking for before generation, 2024. https://arxiv.org/abs/2404.14469.
Liu J, Chung J W, Wu Z, et al. Andes: Defining and enhancing quality-of-experience in llm-based text streaming services, 2024a. https://arxiv.org/abs/2404.16283.
Liu Y, Li H, Cheng Y, et al. Cachegen: Kv cache compression and streaming for fast large language model serving, 2024b. https://arxiv.org/abs/2310.07240.
Liu Z, Yuan J, Jin H, et al. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. arXiv preprint arXiv:2402.02750, 2024c.
llm-d Project. llm-d: A kubernetes-native high-performance distributed llm inference framework. https://github.com/llm-d/llm-d, 2025.
Meta Engineering. Roce networks for distributed ai training at scale. https://engineering.fb.com/2024/08/05/data-center-engineering/roce-network-distributed-ai-training-at-scale/, 2024.
Nie C, Fonseca R, Liu Z. Aladdin: Joint placement and scaling for slo-aware llm serving, 2024. https://arxiv.org/abs/2405.06856.
NVIDIA Corporation. Nvidia dynamo: A datacenter-scale distributed inference serving framework. https://github.com/ai-dynamo/dynamo, 2025.
NVIDIA Developer Forums. Why is the transfer throughput low when transferring small size data (gpu host/device transfers). https://forums.developer.nvidia.com/t/why-is-the-transfer-throughput-low-when-transferring-small-size-data-from-host-to-device-or-device-to-host/153962, 2020.
Patel P, Choukse E, Zhang C, et al. Splitwise: Efficient generative llm inference using phase splitting, 2024. https://arxiv.org/abs/2311.18677.
Qin R, Li Z, He W, et al. Mooncake: Trading more storage for less computation – a KVCache-centric architecture for serving LLM chatbot. In: 23rd USENIX Conference on File and Storage Technologies (FAST 25), Santa Clara, CA, 2025a: 155-170.
Qin R, Li Z, He W, et al. Mooncake: A kvcache-centric disaggregated architecture for llm serving, 2025b. https://arxiv.org/abs/2407.00079.
Qin Z, Cao Y, Lin M, et al. Cake: Cascading and adaptive kv cache eviction with layer preferences, 2025c. https://arxiv.org/abs/2503.12491.
Redis. Redis enterprise software reference – redis documentation. https://redis.io/docs/latest/operate/rs/references/, 2025
Ren Z, Doekemeijer K, De Matteis T, et al. An i/o characterizing study of offloading llm models and kv caches to nvme ssd. In: Proceedings of the 5th Workshop on Challenges and Opportunities of Efficient and Performant Storage Systems (CHEOPS ’25), New York, NY, 2025: 23-33.
Shi X, Cai C, Du J, et al. Nexus: proactive intra-gpu disaggregation of prefill and decode in llm serving, 2025. https://arxiv.org/abs/2507.06608.
Strecker W D. Vax-11/780: A virtual address extension to the dec pdp-11 family. In: Proceedings of the National Computer Conference, Montvale, NJ, 1978: 967-980.
Tang J, Zhao Y, Zhu K, et al. Quest: Query-aware sparsity for efficient long-context llm inference, 2024. https://arxiv.org/abs/2406.10774.
The AIBrix Team, Shan J, Gupta V, et al. Aibrix: Towards scalable, cost-effective large language model inference infrastructure, 2025. https://arxiv.org/abs/2504.03648.
The SGLang Team. Ome: Revolutionizing llm infrastructure with model-driven architecture. https://lmsys.org/blog/2025-07-08-ome/, 2025.
UCCL Team. Everything you want to know about kv cache transfer engine. https://uccl-project.github.io/posts/kv-transfer-engine/, 2025.
vLLM project. vllm production stack: Reference system for k8s-native cluster-wide deployment with community-driven performance optimization. https://github.com/vllm-project/production-stack, 2025.
Xiao G, Tang J, Zuo J, et al. Duoattention: Efficient long-context llm inference with retrieval and streaming heads, 2024a. https://arxiv.org/abs/2410.10819.
Xiao G, Tian Y, Chen B, et al. Efficient streaming language models with attention sinks, 2024b. https://arxiv.org/abs/2309.17453.
Xie Z, Xu Z, Zhao M, et al. Strata: Hierarchical context caching for long context language model serving, 2025. https://arxiv.org/abs/2508.18572.
Yang H, Zhang R, Huang M, et al. Kvshare: An llm service system with efficient and effective multi-tenant kv cache reuse, 2025. https://arxiv.org/abs/2503.16525.
Ye L, Tao Z, Huang Y, et al. ChunkAttention: Efficient self-attention with prefix-aware KV cache and two-phase partition. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 2024: 11608-11620.
Yu L, Lin J, Li J. Stateful large language model serving with pensieve. In: Proceedings of the Twentieth European Conference on Computer Systems (EuroSys ’25), New York, NY, 2025: 144-158.
Zhang H, Ji X, Chen Y, et al. Pqcache: Product quantization-based kvcache for long context llm inference, 2025. https://arxiv.org/abs/2407.12820.
Zhang Y, Li F, Tang Y, et al. Optimizing llm queries in relational workloads. arXiv preprint arXiv:2403.05821, 2024.
Zhao Y, Yang S, Zhu K, et al. Blendserve: Optimizing offline inference for auto-regressive large models with resource-aware batching, 2024. https://arxiv.org/abs/2411.16102.
Zheng L, Yin L, Xie Z, et al. Sglang: Efficient execution of structured language model programs, 2024. https://arxiv.org/abs/2312.07104.
Zhong Y, Liu S, Chen J, et al. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving, 2024. https://arxiv.org/abs/2401.09670.
Zhou Y, Chen Z, Mao Z, et al. An extensible software transport layer for gpu networking. arXiv preprint arXiv:2504.17307, 2025.
